Speech Recognition
Revolutionizing Language Learning with ASR Technology
Automatic speech recognition (ASR), is a technology that uses AI and machine learning techniques to understand and produce spoken and written text. Over the past few years, ASR has seen rapid advancements, becoming more accurate and widely implemented across various industries. In the field of language learning, ASR has played a transformative role, enabling more interactive, personalized, and effective learning experiences. This blog explores how ASR has revolutionized computer-assisted language learning (CALL), the benefits it offers, and the challenges that remain.
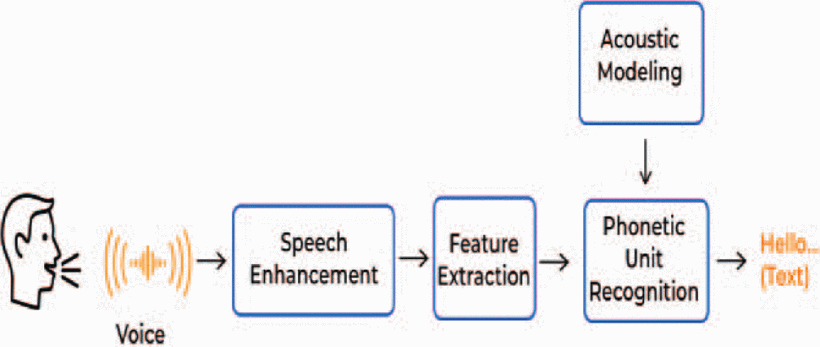
The integration of advanced speech recognition into language learning platforms has led to more interactive and effective educational tools. For instance, Rosetta Stone utilizes TruAccent, a speech-recognition tool that achieves more than just detecting what you’re saying—it’s able to tell you how well you spoke each word or phrase. Additionally, ASR has been used to enhance reading skills by providing individualized feedback. Bai et al (2020) reported that ASR-based feedback improved reading accuracy and speed in Dutch first graders, demonstrating the potential for more personalized and effective reading instruction.
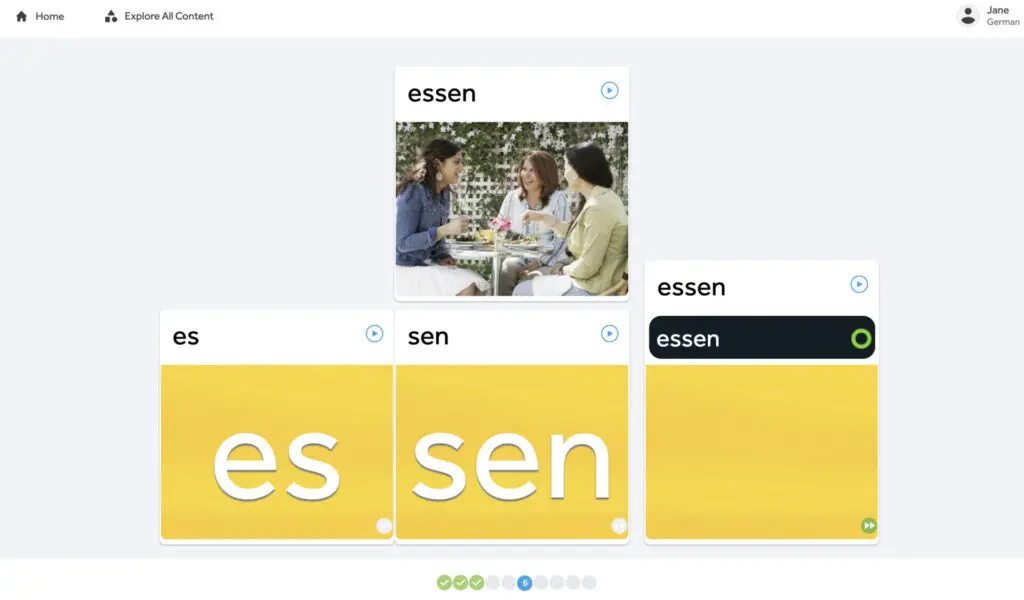
Rosatta Stone TruAccent speech recognition engine
ASR-powered Intelligent Personal Assistants (IPAs) such as Google Assistant and Amazon Alexa have been increasingly integrated into language learning, allowing learners to control the pace and content based on their needs. Studies have shown that learners benefit from interacting with IPAs in a low-stress environment, allowing them to practice pronunciation and fluency at their own pace. (Tai & Chen, 2023) Additionally, ASR enables real-time feedback, helping learners recognize and correct their mistakes instantly. This adaptability is crucial for learners with varying proficiency levels and goals.
Voice-based chatbots have also emerged as a popular tool in CALL, especially for children learning a second language. Research has shown that state-of-the-art ASR models, such as Wav2Vec2.0 and Whisper AI, can achieve acceptable performance even with the challenging nature of child and non-native speech.( Simone Wills et al., 2023) These systems can provide detailed feedback on phoneme pronunciation quality, helping learners improve their fluency and accuracy.
Moreover, ASR technology has advanced CALL by enhancing speech transcription and translation. In 2022, OpenAI introduced Whisper, a machine learning model capable of transcribing speech across multiple languages and translating non-English languages into English, making it a valuable tool for language learners seeking accurate transcription and translation services. Similarly, Speechmatics has made notable contributions by developing speech-to-text engines that excel in transcribing speech in challenging environments. Their 2023 release, Ursa offers high transcription accuracy, which is essential for language learners practicing in varied settings.


Despite the remarkable progress of ASR in language learning, several challenges remain. Achieving high accuracy in speech recognition depends on overcoming factors such as background noise, speaker diversity, vocabulary complexity, and domain specificity. While challenges remain, ongoing research and technological advancements will continue to refine ASR applications, making language learning more effective, interactive, and personalized.